Subtítulo: Um rollout de passkeys bem feito reduz atrito no login, melhora a segurança contra phishing e evita criar uma nova fonte de chamados no suporte.
Passkeys deixaram de ser apenas uma promessa de autenticação moderna e passaram a exigir decisões concretas de produto e engenharia. Para times de tecnologia, o erro mais comum não é técnico: é tratar passkey como um botão mágico que substitui senha da noite para o dia. Na prática, a adoção funciona melhor quando entra como uma camada progressiva, integrada ao fluxo atual de login e acompanhada por gestão clara de credenciais.
Por que passkeys merecem atenção agora
O padrão WebAuthn já amadureceu o suficiente para suportar uma implementação séria em produtos web, e o ecossistema em torno de passkeys também ficou mais claro. A combinação de autenticação resistente a phishing, menor dependência de senhas e experiência mais rápida de entrada cria um ganho direto para segurança e conversão. Mas esse ganho só aparece quando o fluxo respeita o contexto do usuário: dispositivo, provedor de credenciais, fallback e recuperação de conta.
O rollout certo começa pelo login existente
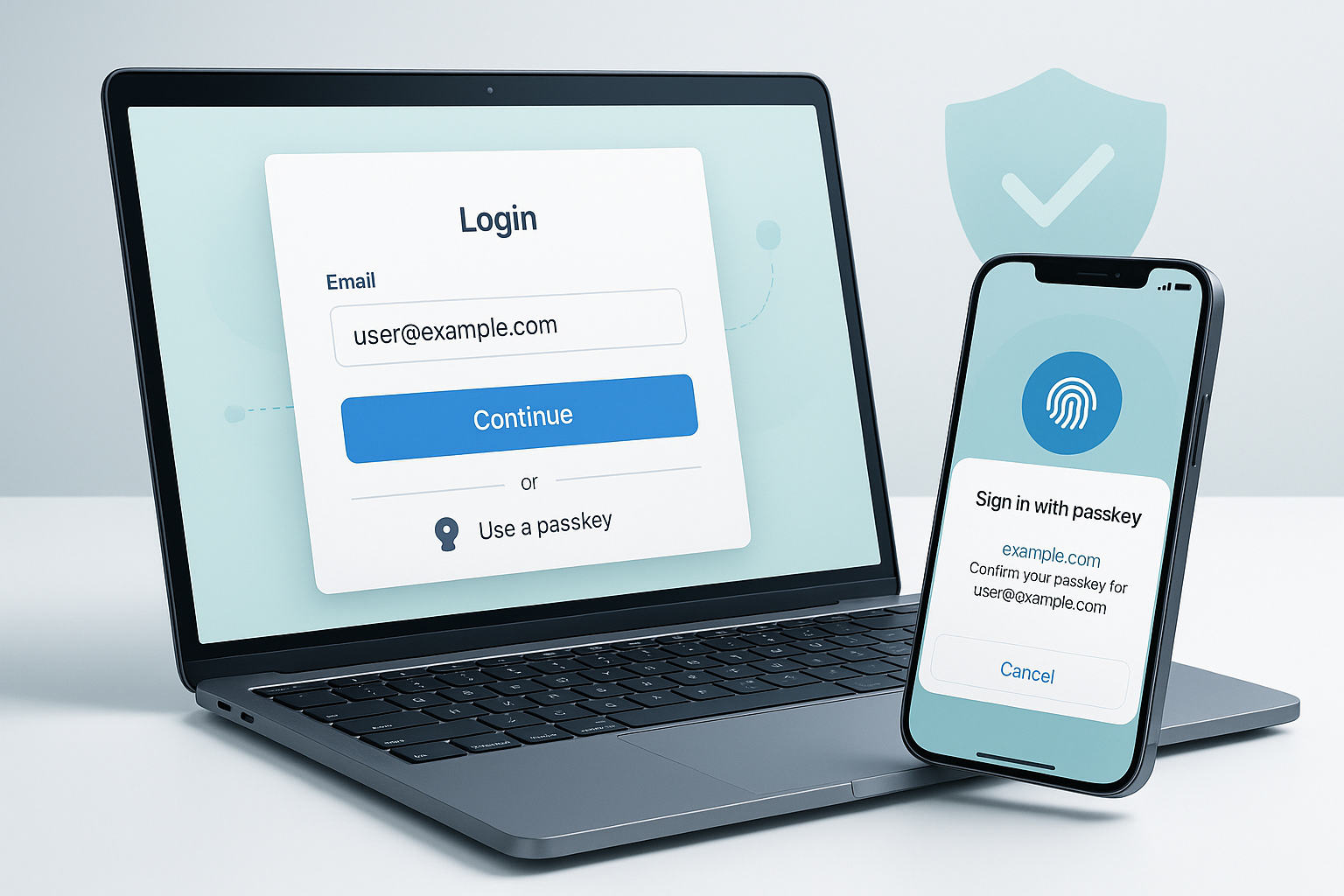
Uma boa estratégia não começa removendo senha, e sim acrescentando passkeys ao fluxo já conhecido. A orientação prática do ecossistema é simples: primeiro identifique o usuário, depois ofereça passkey com autofill condicional e mantenha o login legado como fallback. Isso evita travar pessoas que ainda não criaram credenciais naquele dispositivo ou dependem de outro aparelho para autenticar.
Na implementação web, isso significa:
- mostrar o campo de identificação normalmente, como e-mail ou nome de usuário;
- habilitar o autofill com suporte a WebAuthn quando o navegador e a plataforma permitirem;
- enviar desafios gerados no backend e validar a resposta no servidor;
- continuar oferecendo senha, MFA ou recuperação quando a autenticação com passkey não se resolver.
Esse desenho reduz risco operacional porque o login não fica refém de uma única experiência nova.
O erro que mais gera fricção: não pensar em múltiplas passkeys
Muita implementação inicial funciona bem em demo, mas falha no uso real porque assume apenas uma credencial por usuário. Em produção, a mesma pessoa pode usar notebook corporativo, celular pessoal e um provedor diferente de sincronização. Se o sistema não aceita múltiplas passkeys por conta, o time transforma conveniência em bloqueio.
Além de armazenar várias credenciais públicas por usuário, vale criar uma área simples de gestão. Essa tela deve listar as passkeys registradas, exibir nome identificável, data de criação ou uso recente e permitir remoção. Isso ajuda o usuário a entender o que está ativo e reduz chamados quando há troca de dispositivo, perda de acesso a um provedor ou suspeita de uso indevido.
Regra prática para o backend
Modele passkeys como uma coleção associada ao usuário, não como um atributo único da conta. Também registre metadados suficientes para administração e auditoria leve, como nome amigável, último uso e origem aproximada da credencial.
UX e segurança precisam andar juntas
Passkeys melhoram segurança, mas uma UX ruim ainda derruba adoção. As diretrizes de design da FIDO reforçam que a experiência precisa ser consistente, compreensível e gradual. Em termos práticos, isso significa evitar mensagens vagas, explicar quando a passkey será criada, deixar claro que o desbloqueio do dispositivo fará parte do processo e não esconder o caminho alternativo de entrada.
Outro ponto importante é a verificação do usuário. Em alguns dispositivos, exigir verificação de forma inflexível pode gerar atrito desnecessário. O ideal é equilibrar a política de segurança com a realidade dos aparelhos suportados e validar no servidor se o resultado atende ao nível exigido pela aplicação.
O que muda no suporte e na operação
Adotar passkeys não elimina suporte, apenas muda o tipo de problema. Em vez de redefinição de senha, você passa a lidar mais com gestão de credenciais, troca de dispositivo e entendimento do usuário sobre onde aquela passkey está armazenada. Por isso, o rollout precisa incluir:
- mensagens claras de cadastro e remoção;
- fallback seguro para quem ainda não aderiu;
- fluxo de recuperação que não contradiga o ganho de segurança;
- observabilidade sobre taxa de sucesso do login e abandono por etapa.
Sem esses cuidados, o projeto até funciona tecnicamente, mas perde valor de negócio.
Checklist para implementar com menos retrabalho
- Introduza passkeys como opção adicional antes de pensar em substituição total de senha.
- Use backend com desafio por sessão e validação completa da resposta WebAuthn.
- Permita mais de uma passkey por usuário.
- Crie uma página de gerenciamento de credenciais.
- Mantenha fallback e recuperação consistentes durante a transição.
- Meça adoção, sucesso de login e pontos de abandono.
Para equipes que constroem produtos digitais, passkeys não são apenas um recurso de segurança. São uma decisão de arquitetura, UX e operação. Quando a implementação respeita essa combinação, o resultado costuma ser um login mais rápido, menos dependente de senha e mais sustentável em produção. Se a sua aplicação precisa evoluir autenticação sem sacrificar experiência, a Devcraftstudio pode ajudar a desenhar esse rollout do jeito certo.
Fontes de pesquisa
- Web Authentication: An API for accessing Public Key Credentials – Level 3
- passkeys.dev Bootstrapping
- web.dev Help users manage passkeys effectively
- FIDO Alliance Design Guidelines for Passkeys